1. 숫자 연산
| sqrt() | 주어진 값의 제곱근 |
| abs() | 주어진 값의 절댓값 |
| exp() | 자연상수 e의 제곱수 |
| log() | 밑이 자연상수인 로그 값 |
| log10() | 밑이 10인 로그 값 |
| pi() | 원주율 pi=3.141592 |
| round() | 주어진 수의 반올림 값 |
| ceiling() | 주어진 수를 올림 |
| floor() | 주어진 수를 내림 |
2. 문자 연산
| tolower() | 주어진 문자열을 소문자로 변경 |
| toupper() | 주어진 문자열을 대문자로 변경 |
| nchar() | 주어진 문자열의 길이 |
| substr() | 문자열의 일부분을 추출 |
| strsplit() | 문자열을 구분자로 나누어 쪼갬 |
| grepl() | 문자열에 주어진 문자가 있는지 확인 |
| gsub() | 문자열의 일부분을 다른 문자로 대체 |
> data<-'This is a pen'
> tolower(data)
[1] "this is a pen"
> toupper(data)
[1] "THIS IS A PEN"
> nchar(data)
[1] 13
> substr(data, 9, 13)
[1] "a pen"
> strsplit(data, 'is')
[[1]]
[1] "Th" " " " a pen"
> grepl('pen', data)
[1] TRUE
> gsub('pen', 'bananan', data)
[1] "This is a bananan"
3. 벡터 연산
| length() | 주어진 벡터의 길이 |
| paste() | 주어진 벡터를 구분자를 기준으로 결합 |
| cov() | 두 수치 벡터의 공분산 |
| cor() | 두 수치 벡터의 상관관계 |
| table() | 데이터의 개수 |
| order() | 벡터의 순서 |
4. 행렬 연산
| t() | 전치행렬 |
| diag() | 대각행렬 |
| %*% | 두 행렬을 곱함 |
> m1<-matrix(c(1,2,3,4,5,6), nrow=2)
> m2<-matrix(c(1,2,3,4,5,6), ncol=2)
> m1
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
> m2
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
> m1%*%m2
[,1] [,2]
[1,] 22 49
[2,] 28 64
5. 데이터 탐색
| head() | 데이터의 앞 일부분 출력 |
| tail() | 데이터의 뒤 일부분 출력 |
| quantile() | 수치 벡터의 4분위수를 출력 |
> x<-c(1 : 12)
> head(x, 5)
[1] 1 2 3 4 5
> tail(x, 5)
[1] 8 9 10 11 12
> quantile(x)
0% 25% 50% 75% 100%
1.00 3.75 6.50 9.25 12.00
6. 데이터 전처리
| subset() | 데이터에서 조건식에 맞는 데이터를 추출 |
| merge() | 두 데이터를 특정 공통된 열을 기준으로 병합 |
| apply() | 데이터에 열(또는 행)별로 주어진 함수를 적용 |
> df1<-data.frame(x=c(1, 1, 1, 2, 2), y=c(2, 3, 4, 3, 3))
> df2<-data.frame(x=c(1, 2, 3, 4), z=c(5, 6, 7, 8))
> subset(df1, x==1)
x y
1 1 2
2 1 3
3 1 4
> merge(df1, df2, by=c('x'))
x y z
1 1 2 5
2 1 3 5
3 1 4 5
4 2 3 6
5 2 3 6
# 1은 행에 함수를 적용, 2는 각 열에 함수를 적용
> apply(df1, 1, sum)
[1] 3 4 5 5 5
> apply(df1, 2, sum)
x y
7 15
7. 정규분포(기본값은 표준 정규 분포 mean=0, sd=1)
| dnorm() | 정규 분포의 주어진 값에서 함수 값 구함 |
| rnorm() | 정규 분포에서 주어진 개수만큼 표본을 추출 |
| pnorm() | 정규 분포에서 주어진 값보다 작을 확률을 구함 |
| qnorm() | 정규 분포에서 주어진 넓이 값을 갖는 x 값을 구함 |
8. 표본추출
| runif() | 균일 분포에서 주어진 개수만큼 표본을 추출 |
| sample() | 주어진 데이터에서 주어진 개수만큼 표본을 추출 |
9. 날짜
| Sys.Data() | 연, 월, 일을 출력 |
| Sys.time() | 연, 월, 일, 시간을 출력 |
| as.Date() | 주어진 데이터를 날짜 형식으로 변환 |
| format() | 원하는 날짜 형식으로 변경 |
| as.POSIXct() | 타임스탬프를 날짜 및 시간으로 변환 |
> Sys.Date()
[1] "2021-09-02"
> Sys.time()
[1] "2021-09-02 17:18:43 KST"
> as.Date('2020-01-01')
[1] "2020-01-01"
> format(Sys.Date(), '%Y/%m/%d')
[1] "2021/09/02"
> format(Sys.Date(), '%A')
[1] "Thursday"
> unclass(Sys.time())
[1] 1630570790
> as.POSIXct(unclass(Sys.time()), origin='1970-01-01')
[1] "2021-09-02 17:20:21 KST"
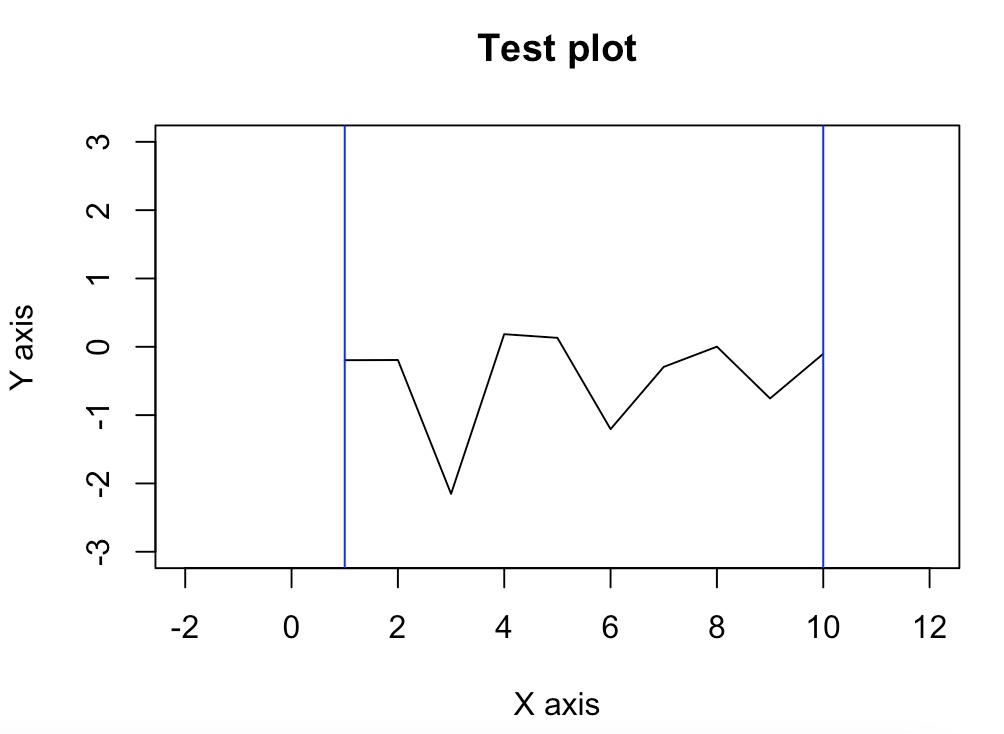
10. 산점도
| plot() | 주어진 데이터의 산점도를 그린다. |
| abline() | 산점도에 추가 직선을 그린다. |
type에서 p는 점, l은 직선, b는 점과 직선, n은 아무것도 표시하지 않음을 의미
xlim로 x축의 범위, ylim으로 y축의 범위를 설정
xlab, ylab은 각 축의 이름을 지정한다.
main으로 산점도의 이름을 지정
abline()
abline()의 v는 수직선, h는 수평선을 그리는 매개변수이다.
col 매개변수로 색상을 지정할 수 있다.
> x<-c(1:10)
> y<-rnorm(10)
> plot(x, y, type='l', xlim=c(-2, 12), ylim=c(-3, 3), xlab="X axis", ylab='Y axis', main='Test plot')
> abline(v=c(1, 10), col='blue')
11. 파일 읽기
| read.csv() | CSV 파일 불러옴 |
| write.csv() | 주어진 데이터를 CSV 파일로 저장 |
| saveRDS() | 분석 모델 및 R 파일을 저장 |
| readRDS() | 분석 모델 및 R 파일을 불러옴 |
12. 기타
| install.packages() | 패키지를 설치 |
| library() | 설치된 패키지를 호출 |
| getwd() | 작업 디렉터리를 확인 |
| setwd() | 작업 디렉터리를 설정 |